目次
統計ツールが吐き出したセグメントに困惑した経験はありませんか
クラスター分析をかけてみたものの、「このセグメント、一体誰なんだろう」と頭を抱えた経験を持つマーケターは少なくありません。筆者もクライアントの調査プロジェクトで何度もその場面に遭遇してきました。
ツールが吐き出した結果は、統計的には正しい分類です。似た回答パターンを持つ人々が確かにグルーピングされています。しかし、それが施策に落とせるかというと話は別です。「クラスター1は全体的に高得点層」「クラスター2はなんでも肯定的に回答する層」といった、実体のないセグメントが出現してしまうのです。
クラスター分析は、意識や価値観といったはっきり定まっていない指標によって分類を行う手法として、マーケティングリサーチの現場で長年使われてきました。理論上は美しく、プレゼンテーション資料にも映えます。しかし実務の最前線では、この手法が抱える構造的な問題が次々と顕在化します。
本記事では、クラスター分析がなぜ実務で使いにくいのか、その根本的な理由を3つの視点から掘り下げます。そして現場が本当に必要としている顧客理解の方法について、定性調査との組み合わせを軸に提案します。
クラスター分析の基本的な仕組みと実務での位置づけ
クラスター分析は、多種多様なものが混在した集団の中から似たもの同士を仕分けてグループ化する手法です。アンケート調査で収集した意識データや行動データを投入すると、統計ソフトが自動的に回答者を複数のグループに分類してくれます。
手法には大きく階層クラスター分析と非階層クラスター分析の2種類があります。階層型はデンドログラムと呼ばれる樹形図を作成し、データ同士が統合されていく過程を視覚的に把握できます。一方で非階層型は、あらかじめクラスター数を決めて分類する方法で、大規模データの処理に適しています。
マーケティング実務では、顧客セグメンテーションやポジショニング分析、ターゲット選定などで活用されてきました。デモグラフィック情報による分類とはまた違った分類が可能という点が、この手法の魅力として語られます。年齢や性別といった属性ではなく、価値観や行動パターンで顧客を分けられるという触れ込みです。
しかし実際にプロジェクトを進めると、この「魅力」が実務上の「落とし穴」に変わることがあります。
理由1:分析結果の解釈が分析者の主観に大きく依存してしまう
クラスター分析の最大の問題は、それが本当に一番良い方法であることを客観的に示すことは可能なのかという根本的な疑問です。クラスター分析はあくまで箱にデータを振り分けるだけであって、その箱に具体的なラベルを付けるのは分析者自身なのです。
たとえば食品メーカーの顧客分析でクラスターが6つ形成されたとします。それぞれを「ヘルシー層」「スイーツ層」「ガッツリ層」と命名するのは分析者の解釈です。本来「ヘルシー層」であるべきクラスターを「ガッツリ層」と誤って解釈すれば、その後のマーケティング施策はすべて誤った方向に進みます。
クラスタリングの結果は絶対的でも、普遍的でも、客観的でもないので、分割結果は結論を導く証拠にはなりえません。同じデータでも、クラスター数を3にするか5にするかで結果は変わります。距離の測り方を変えても結果は変わります。7だと多いけれども3では少ない気がしたから4から6でやってみたら5がしっくりいったという納得感は、科学的な妥当性とは別物です。
さらに厄介なのは、なんでもポジに答える人たちや、どれにも反応しない人たちが出現することです。これはアンケートの回答傾向のクセが強い人同士がまとまってしまう現象で、「高感度層」という実体のないクラスターが最大セグメントになってしまうこともあります。
調査会社の立場からすると、これを「テキトー回答」とは言いづらい空気があります。しかしターゲットとして設定するには違和感がある。この板挟みが、実務の現場でクラスター分析を使いにくくしている大きな要因です。
理由2:クラスターに名前をつけても施策に落とし込めない抽象性
仮にクラスターの解釈がうまくいったとしても、次に待ち構えているのは「で、どうするのか」という実務上の壁です。
セグメンテーションをしても、実際のお客さまがどういう人かがわからず、購買に至る動機や解決したい課題は何か、またどうやってつながればいいのかなどがなかなか見えてこないのです。「健康意識が高い層」というセグメントが抽出されても、その人たちが朝何時に起きて、どのメディアに接触し、何に悩んでいるのかは見えません。
クラスター分析は統計的な距離に基づいてグルーピングを行うため、どうしても抽象的な特徴の羅列になります。各クラスターの平均値を比較して「このクラスターはA項目が高くB項目が低い」という記述はできますが、それが具体的な生活者の姿とは結びつきにくいのです。
マーケティング施策を立案する現場では、「誰に」「何を」「どこで」「どうやって」届けるかが具体的に見えなければ動けません。クラスター分析の結果は、この「誰に」の解像度が低すぎることが多いのです。クラスター分析の結果から、属性に寄らない、ユーザー像というのが見えてきますという説明がなされますが、実際には「見えてくる」までにかなりの補完作業が必要になります。
さらに、各指標の得点範囲というデータ分析の目的と本質的に関係がない特徴によって、距離計算に想定外の偏りが生じる問題も見逃せません。5件法で測定した項目と7件法で測定した項目を一緒にクラスター分析にかけると、得点範囲の大きい指標によって距離が左右され、範囲が小さい指標の特徴はほとんど反映されなくなります。標準化という前処理で対応可能ですが、この技術的な落とし穴に気づかず分析を進めてしまうケースは少なくありません。
理由3:定量データだけでは人間の文脈が捉えられない
クラスター分析が実務で機能しにくい最大の理由は、この手法が定量データだけに依存している点にあります。定量的な調査では、ユーザがどのくらいの人数で、どのようなユーザがいるかといったことを理解するのに適しています。一方、定性的な調査では、なぜ、どのようにといったことを明らかにします。
アンケートの選択肢で測定できるのは、あくまで表層的な態度や行動です。その背後にある「なぜその選択をしたのか」「どんな文脈でその行動が生まれたのか」という人間の営みは、数値化された瞬間に失われます。
たとえば「健康のために運動している」という回答が同じでも、ある人は医者に警告されて仕方なく始めたのかもしれないし、別の人は自己実現の一環として楽しんでいるのかもしれません。この違いは、施策設計において決定的に重要です。しかしクラスター分析では、両者は同じ「健康意識高い層」にまとめられてしまいます。
もしそのペルソナがとてもニッチなセグメントに属する人であったとしたら、そしてそのペルソナに基づきマーケティング戦略を組み立てたとしたらその結果は悲惨なものにあるであろうことは明らかです。しかし逆に、定性調査だけでペルソナを作っても市場規模の裏付けがなければ意思決定には使えません。
この定量と定性のギャップを埋めることこそが、実務で成果を出すための鍵になります。
では実務で使える顧客理解はどう作るのか
クラスター分析の限界を理解した上で、では実務者はどうすればよいのでしょうか。答えは、定性調査を起点に顧客理解を深め、必要に応じて定量調査で検証するというアプローチです。
定量調査手法はメリットがあるが、しばしばデザインのためのインサイトに欠け、そこから新しいものを開発するインスピレーションを得ることが出来ない。一方、定性調査手法は人間中心設計のデザイナーに不可欠なインスピレーションを与えてくれるが、その定性調査で明らかにされたインサイトは、そこに市場の代表性があるという数字的根拠がなければ薄っぺらなものになってしまう。このバランスが重要です。
まずデプスインタビューや行動観察調査を実施して、顧客の生活文脈や意思決定プロセスを深く理解します。そこから見えてきたパターンをもとに仮説としての顧客セグメントを設定し、ペルソナを作成します。
ペルソナからターゲット像を作成することで、現実に存在している実感のあるターゲット像とそのコンテクストシナリオが作成できます。その上でペルソナ自体の市場規模を推定することで、通常のセグメント分析と同様に、規模の大きい、ポテンシャルの高いペルソナをターゲットにできます。
この手順なら、定性調査で得られた生き生きとした顧客像を保ったまま、定量的な妥当性を担保できます。クラスター分析のように「統計ソフトが分類した結果をどう解釈するか」で悩む必要はありません。顧客理解が先にあり、数字は後からついてくるという順序です。
1対1の対面形式でじっくりと対話を行うことで、アンケートの選択肢には現れない無意識のこだわりや背景にあるライフスタイルを浮き彫りにできます。朝起きてから寝るまでの詳細な行動動線、検討段階での迷い、最後の決め手となった一言。こうした情報があってはじめて、施策に落とせるターゲット像が完成します。
定性調査とペルソナを軸にした顧客理解の実践プロセス
具体的なプロセスを提示します。まずターゲット市場の中から多様な背景を持つ対象者を選定し、インタビュー調査を実施します。この段階では網羅性を意識し、ユーザー、ノンユーザー、ライトユーザー、ヘビーユーザーなど様々な立場の人に話を聞きます。
インタビューでは、行動の背景にある動機、感情、価値観を丁寧に掘り下げます。モデレーターの技量が問われる場面ですが、ここで得られる質的データが後の顧客理解の解像度を決定します。
次に、インタビューから見えてきたパターンをもとに、代表的なユーザー像を3〜5体程度のペルソナとして具体化します。このペルソナには、単なる属性情報だけでなく、生活シーン、悩み、情報接触チャネル、意思決定のプロセスなどを盛り込みます。物語の登場人物を描写するようにストーリー形式で記述してみることで、実在感のある人物像を描き出しやすくなります。
その上で、作成したペルソナが市場にどの程度存在するのかを定量調査で検証します。アンケート調査を設計し、ペルソナを特徴づける質問項目を設定します。定量アンケートを実施し、定性的に作成したペルソナが市場に実際に存在しているかの妥当性を、定量解析によって検証。結果を踏まえてペルソナを調整します。
この方法なら、クラスター分析のように「結果が出てから解釈に困る」という事態を避けられます。顧客理解が先にあり、数字はその裏付けとして機能するからです。
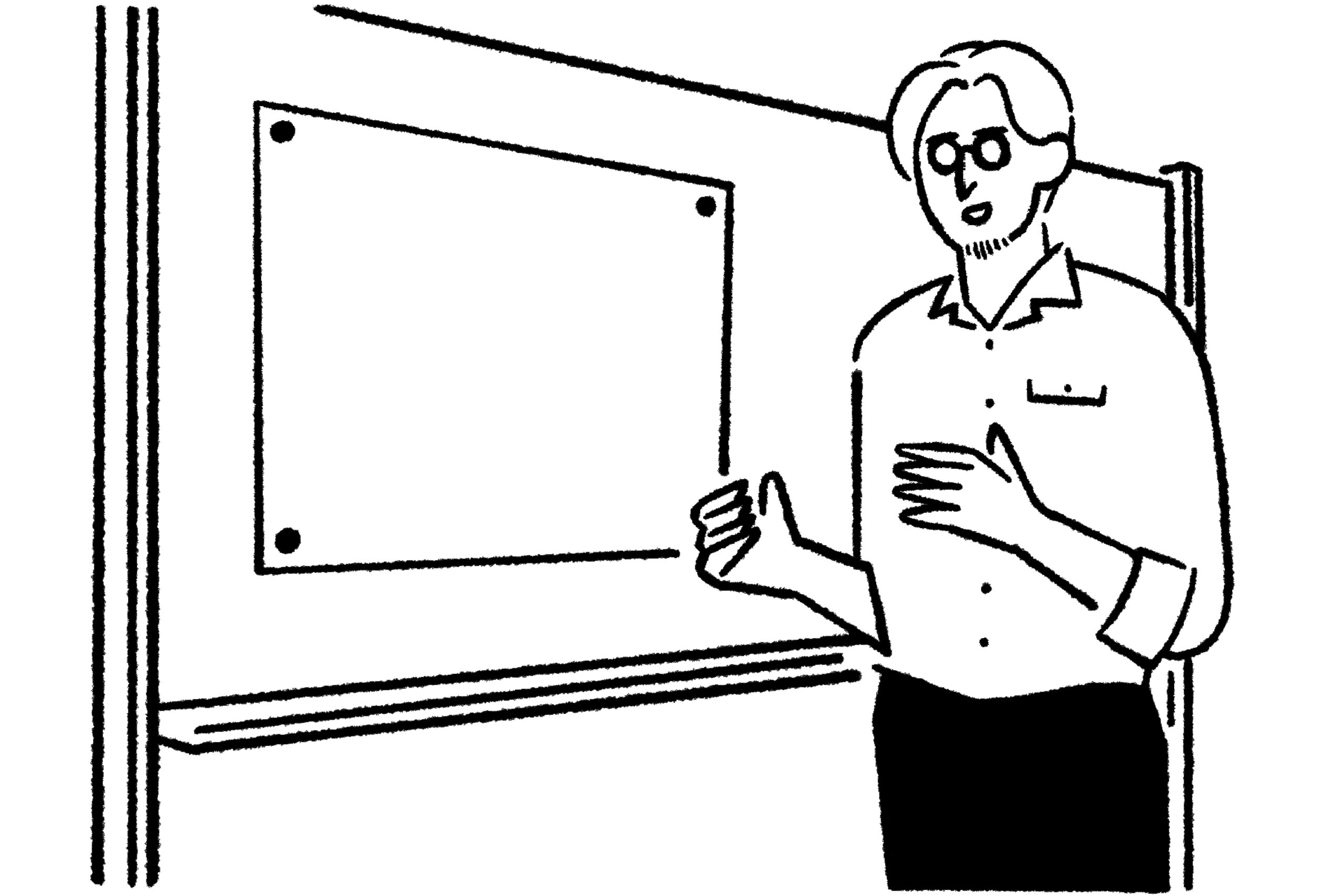
現場で実際に使えるアウトプットとは何か
実務で本当に必要なのは、統計的に美しいセグメンテーションではありません。施策に落とせる具体性を持った顧客像です。
たとえば広告クリエイティブを作る際、「30代女性、健康意識高め」というセグメント情報では何も作れません。しかし「朝5時に起きてヨガをする34歳の佐藤さん。会社員で管理職を目指しているが、最近体力の衰えを感じている。インスタで情報収集し、口コミを重視する。夜はNetflixを見ながらプロテインを飲む」というペルソナがあれば、訴求メッセージもビジュアルも具体的にイメージできます。
ペルソナを活用することで、誰のために何をするのかをより理解できるようになります。商品開発、コミュニケーション戦略、チャネル選定、すべての意思決定において、ペルソナは判断軸として機能します。
また、社内でのコミュニケーションも円滑になります。「クラスター2の人たちに向けて」と言うより「佐藤さんみたいな人に向けて」と言う方が、関係者全員が同じイメージを共有できます。このシンプルな違いが、施策の実行力に大きく影響します。
クラスター分析が得意とする市場規模の把握や傾向分析は、ペルソナの検証フェーズで活用すればよいのです。顧客理解の主役ではなく、脇役として機能させる。この位置づけの転換が、実務での成果につながります。
統計手法を盲信せず顧客の文脈を捉える姿勢が成果を生む
クラスター分析が実務で使いにくい理由をまとめます。第一に、分析結果の解釈が分析者の主観に大きく依存し、客観的な正しさを証明できない点。第二に、クラスターに名前をつけても施策に落とし込めない抽象性が残る点。第三に、定量データだけでは人間の文脈が捉えられない点です。
これらの問題は、クラスター分析という手法そのものの限界であり、使い方が悪いという話ではありません。統計的に正しい分類と、実務で使える顧客理解は、必ずしも一致しないのです。
実務者に求められるのは、統計手法を盲信せず、顧客の文脈を捉える姿勢です。定性調査で顧客の生活に入り込み、そこから見えてきたパターンを定量調査で検証する。この順序を守ることで、施策に落とせる顧客理解が生まれます。
クラスター分析が完全に不要というわけではありません。しかしそれは、顧客理解の出発点ではなく、検証ツールとして位置づけるべきです。顧客の文脈を捉えたカスタマージャーニーの設計や、実在感のあるペルソナの構築には、定性調査が不可欠です。
統計ソフトが吐き出した美しいデンドログラムに惑わされず、生活者の声に耳を傾ける。その泥臭いプロセスこそが、マーケティング実務で成果を出すための王道です。
リサートにマーケティングリサーチの相談をする


よくある質問
クラスター分析で出てきた結果が、実務で使えない抽象的なセグメントになってしまうのはなぜですか?
クラスター分析は統計的に似た回答パターンをグループ化するだけで、その結果に具体的な意味を付けるのは分析者の主観に依存するためです。例えば、高い評価をつける人同士がまとまって「高感度層」というセグメントになっても、実際にはアンケート回答のクセが強い人々の集まりに過ぎず、マーケティング施策に落とし込める実体がありません。
クラスター数を3にするか5にするかで結果が変わるというのは、分析手法として信頼できないということですか?
その通りです。クラスター分析では距離の測り方やクラスター数の設定次第で結果が大きく変わります。同じデータでも分析者の判断で異なる結果が得られるため、統計的に正しいという理由だけでは、マーケティング施策の根拠として十分な客観性がないと言えます。
顧客セグメンテーションをする際に、クラスター分析の代わりに何を使うべきですか?
定性調査とペルソナを軸にした顧客理解が有効です。定量データだけでは捉えられない顧客の文脈や背景、実際の行動理由を深掘りすることで、マーケティング施策に直結する実体のあるセグメンテーションが可能になります。
この記事を書いた人

リサート所属モデレーター。外資系コンサルティング・ファーム等を経て現職。生活者への鋭い観察眼と洞察力を強みに、生活者インサイトの提供を得意とする。2022年より株式会社バイデンハウス代表取締役。2025年よりインタビュールーム株式会社(リサート)取締役。